我把memos:stable迁移到内网的k3s集群上来降本增效了,而且还能体验一下k3s。
刚开始时直接使用的pvc是nfs,数据库仍然使用sqlite,结果部署后实际进行访问才发现首页数据加载要等个1s多,根本不像内网的速度。
想一想就知道了:sqliteIO -> nfsIO -> 机械硬盘IO,这一趟下来性能可太差了。更何况nfs本身性能就不好,机械硬盘速度也慢,随机IO性能非常一般。因此打算直接迁移到postgresql,而为了增强毫无必要的可靠性,我的postgresql安装在了另一个新的机器中,而不是k3s集群上。
配置了数据库后就计划迁移了,原本打算用一些工具比如heidisql把sqlite的数据导出成sql文件,然后在postgresql上执行一遍来完成数据迁移。但是执行过程中发现由于创建表等的语法差异太大,根本无法成功。
官网上有贴出一个chatgpt的问答展示如何把数据从sqlite迁移到mysql,担心不适用于我的情况我就没有细看。
因此打算转变方向:通过观察两个数据库上的表的设计,发现表结构相对简单,而且主要数据都集中在memos表。所以尝试先让memos初始化postgresql数据库,然后执行相对通用的每个表单独的insert命令来导入数据。
首先遇到的问题是,memos表的pinned列在sqlite中为integer类型,而pgsql中为boolean类型,直接导入会报错,需要把这列的所有insert命令的数据从0改为false,1改为true。
接下来需要修改自增ID的当前值,来避免重复插入的错误。
在sqlite上执行
1 | |
获取当前的各sequence的值(最新的自增id),然后在pgsql上执行
1 | |
来修改sequence,以下为一个例子:
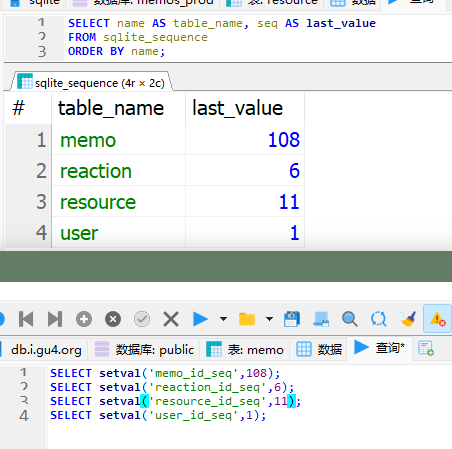
经过测试,发现可以正常进行所有工作,因此我大概是迁移成功了。
另外,我还发现使用s3作为存储时,存储上传文件的表的blob列在sqlite中为空,而在postgresql则具有默认值\x,暂时不知道是否会出现兼容性问题。
最后,在观察表结构后我认为:由于表结构相对简单,因此直接让AI生成迁移脚本应该是十分容易的,但是之前我怕出现意外最终还是半手动半自动地进行了。

djh
事已至此,先吃饭吧