在上一篇文章中我简单讲述了在实现kaleidoscope编译器前端的实现过程中出现的问题和解决方案。
在跟随教程实现前端后,感觉不够尽兴,因为没有拿这个语言具体实现什么比较复杂的有意思的东西,所以我一寻思:要不做一个在kaleidoscope上的brainfuck解释器吧!
拓展编译器
显而易见,跟着教程实现的编译器有太多的不足,例如由于此语言的变量类型只有double类型,其他任何类型都不支持,更没有数组这种高级玩意儿。即使打印hello world都需要一个字符一个字符的输出,因此我们需要拓展此编译器,让它支持更多功能,来完成我们的目标——实现brainfuck解释器。
添加更多flag
为了更好调试和使用自己实现的编译器,我们需要设置一些开关来启用或关闭编译器的功能。这是我为了方便自己使用,设置的几个flag
1 | |
jit::ECHO_RETURN_VALUE是否打印当前表达式的返回值jit::ECHO_PROMPT是否打印promptjit::ECHO_IR_CODE是否打印函数定义的LLVM IR代码jit::ONCE_IGNORE_RETURN_VALUE是否只忽略一次不打印返回值(一般用于库函数进行打印的场景)ast::CSTYLE_FOR_EXPRC风格for循环的条件检查ast::OPTIMIZATE_CODE是否优化代码
其中,值得一提的是CSTYLE_FOR_EXPR。官方教程的for循环实现的循环体的运行流程是这样的
- 执行循环体内部代码
- 为条件变量添加step值
- 检查条件是否满足,满足则跳转到开头
这产生了一个问题:即使条件不满足,for循环的循环体也会至少被执行一次,和我以往学的for循环风格对条件检查放在循环体开始之前相去甚远,虽然也能写,但是为了习惯我修改了for循环的codegen部分,通过引入一个新的用于条件判断并跳转的loopcond块,将进入和退出loop块修改指向到loopcond块来实现。从而将循环体的执行流程修改为
- 检查条件是否满足,满足则跳转出循环
- 执行循环体内部代码
- 为条件变量添加step值
- 跳转到开头
函数原型同时支持以空白字符和逗号分隔
写C系太多导致的 习惯这样写了。
教程描述的function prototype的语法为def F(X Y Z)或者extern F(X Y Z)。但是调用函数又加逗号F(1,2,3)为了统一风格,我实现了同时支持空白字符和逗号作为分隔符,例如def F(X,Y,Z),理论上甚至支持def F(X Y,Z)。
在lexer上实现解析ASCII字符为double数字
虽然lexer不应该负责这个,但是在更上层的parser写又复杂化了,总之通过'H这种单引号后跟一个字符的形式实现了对字符的支持,它会在lexer中被直接转换为一个数字token,所以对上层来看其实并没什么大改变的同时又能输入字符了,真的是很有用的提升。
指定fp读取字符
官方通过getchar读取字符,只能从标准输入读取数据,用起来很不方便,因此我包装了getc,实现设置fp并让lexer从中读取字符解析tok。
库拓展
只用官方的几个库函数,基本是不能简单实现brainfuck的解释器的,不得不拓展。
flag控制
引入flagup和flagdown两个函数用于控制flag。
脚本加载
实现从文件路径加载程序,主要通过前文提到的指定fp读取字符实现。
内存管理
brainfuck至少要求两个“纸带”,一条指令一条数据。虽然我们可以用非常非常多的变量来模拟这个纸带读取过程——通过不同下标读取不同变量,但是为了省事还是加上内存管理的实现吧。
分配和释放堆内存
由于变量只具有double类型,因此不能正常存储指针(我无法判断指针类型和double的相互转换是否会丢数据)因此需要专门创建一个map来存储映射关系,所以引入块内存和块池的概念,使用newblk创建指定大小的堆内存,并返回block index,通过block index进行具体操作。类似于文件指针概念。另外还可以使用freeblk释放内存。
块的访问
我的库函数提供了两种长度的堆内存访问,分别是char(byte)和double。
mreadb(double bi, double byte_idx)对指定的block index,读取指定byte index的字节mwriteb(double bi, double byte_idx, double B)如上,但是写入mreadd(double bi, double double_idx)对指定的block index,读取指定double index的doublemwrited(double bi, double double_idx, double v)如上,但是写入
通过堆内存管理,我们不仅在保持变量仍然只有double类型的基础的同时,实现一种近似于数组的使用方式,还得到了持久化数据存储的能力(相对于作用域只能在当前作用域及其子作用域的函数参数和var-in语句)。
实现brainfuck解释器
我的所有代码都在CSTYLE_FOR_EXPR的flag设置为true的条件下运行,另外添加了官方在User-defined Operators中的各种拓展的操作符函数作为初始化时加载的init代码。
1 | |
可以看到我注释掉了binary=,由于赋值本身也是个binary operator;返回右值,判断相等也是个binary operator,两者无法区分,这可能也是很多编译器设置==为相等的原因吧。总之我注释掉了这个自定义的操作符,转而添加一个eq函数作为判断相等的函数(这时候又有点shell的感觉了哈)。
向前查找[与向后查找]
brainfuck中包含两个操作符用作流程控制,分别是 [ 和 ]。所以要实现两个函数用于查找某位置之前[和之后的]的位置。
1 | |
如果没找到字符串会返回输入的idx。通过一个count模拟了栈的行为,实现查找匹配的中括号。
只有开始写代码才会发现现在这个for真的非常不好用,甚至没有break不能直接打断执行流。
创建纸带
接下来我们需要创建“纸带”,也就是指令数组和内存数组,并接收用户输入将数据存储到指令数组,还有手动重置内存为0。
1 | |
这个BFinit函数实现了重置指令数组为0,存储指令到数组,打印数组,给数据数组置零这几个步骤。
实现解释器状态机
1 | |
这个函数实现了从指令纸带中读取数据,根据读取到的指令更新数据纸带的状态,或者进行io与修改pc。
测试
执行BFinit函数,输入指令
1 | |
执行BFstart函数,查看输出
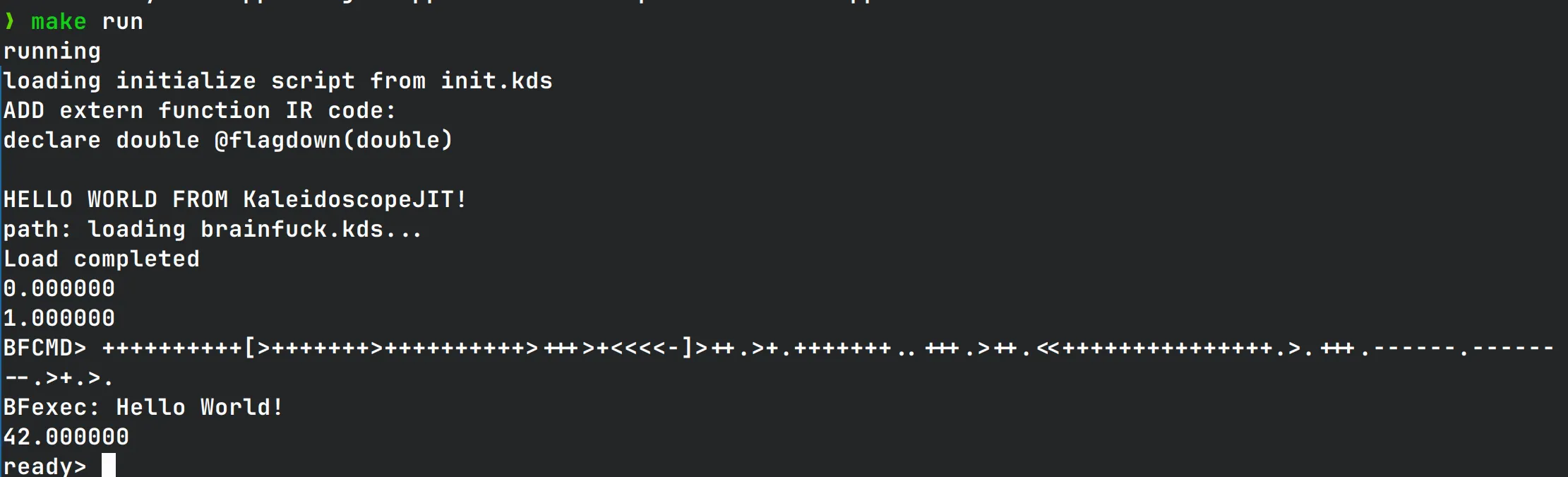
可以看到能正常解释运行,并输出Hello World!,说明解释器的条件循环跳转指针移动都在正常工作。
总结
在自己实现的不完整的编译器上编写代码非常受限,犹如戴着镣铐跳舞,但是好在最后实现了一个简单的brainfuck解释器。
虽然前端实现看起来没什么工作量,而且还有llvm教程,对着抄几乎不会出错。但是这也是一次编译原理的部分理论的简单实践:CFG、EBNF利用有限状态机进行编写,LL(1)解析的具体实现,手动生成AST并进行语义检查,最终发射到llvm进行JIT或者AOT。整个流程下来对编译原理和编译的整个过程(主要是前端)有了大概的了解。

djh
事已至此,先吃饭吧